背景
推送服务起初开发的用途很简单,就是用来解决基于dui上开发的语音产品发布新版本后,将升级信息推送给搭载了思必驰语音sdk的设备上的需求。去年下半年完成重构的版本后,前后演进了三个版本,这篇文章主要来聊一聊这个服务整体的演进的过程以及为什么要做这些改动。
第一版
服务设计
 第一版代码不是我开发的,临时接手做第二版的时候大致看了一下代码,逻辑比较简单,或者说是仅仅实现了一个可用的原型。整个服务是一个基于openresty的websocket+redis的pub/sub开发的推送服务。
第一版代码不是我开发的,临时接手做第二版的时候大致看了一下代码,逻辑比较简单,或者说是仅仅实现了一个可用的原型。整个服务是一个基于openresty的websocket+redis的pub/sub开发的推送服务。
每个客户端连接到服务后,服务会启动两个协程
- recv协程负责接收客户端上行的报文,然后将接收到的报文放入一个非阻塞的队列
- send协程负责消费这个队列的数据,它会重复做以下逻辑
- 如果队列有数据则解包根据协议做业务处理
- 如果没有数据则会建一条连接到redis,订阅指定的topic (product_id + alias_key), 如果订阅到消息,则将消息放入队列
解决的问题
这样借助于redis的发布订阅模式,完成了从0到1的基本可用,实现起来简单粗暴,算是短期投入产出比最高的方式。
存在的问题
上线后随着设备数量的增长,每个服务实例客户端连接数达到3000之后,服务到redis连接数随着设备数一起做线性增长,终于redis扛不住了,已经影响到业务了,重构迫在眉睫。
第二版
第一版最大的问题是服务到redis的连接不够用,解决的方案也很简单,借助redis的psubscribe, 我们可以很快的实现一个subscribe协程,由这个协程批量订阅pattern,然后在服务内部查找需要推送的连接,这样服务到redis的连接数量从N:N下降到了N:1, 即每个服务实例上有N个客户端连接也只需要 1个redis连接。
服务设计
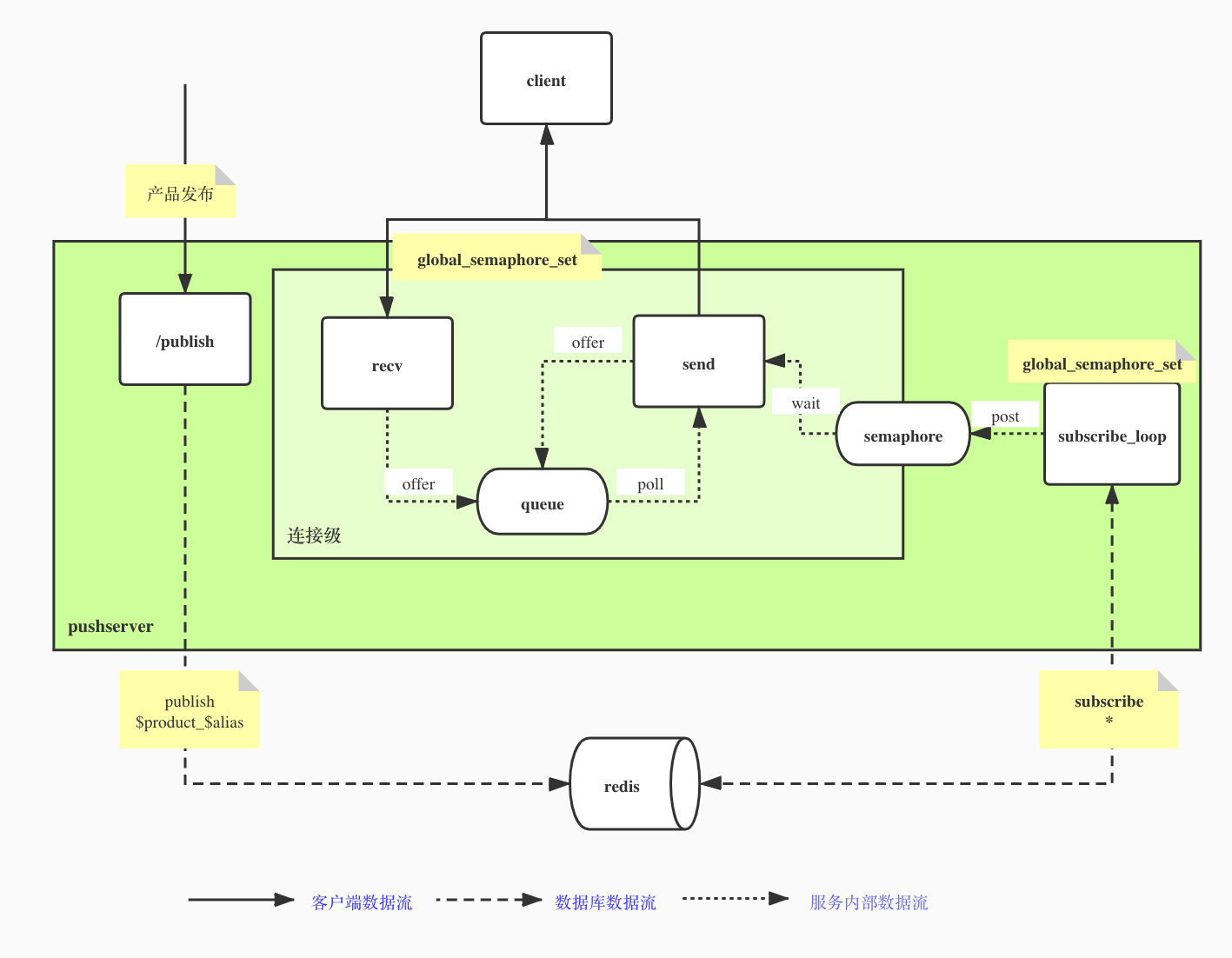
实现上借助nginx的semaphore我们可以实现同一个worker内的跨请求通信。服务启动时按(product_id+alias_key)维度创建一个全局的信号量表(global_semaphore_set),每次连接上来时查找信号量是否存在,如果存在则直接wait, 如果不存在则新建一个并加到全局的信号量组后wait。
通过引入一个全局的subscribe协程,利用redis的psubscribe,接收到topic消息后,解析出要推送的信号量的组,将待推送的消息放入共享内存中,然后获取有多少个连接在wait这个信号量,调用post释放对应数量的临界区资源以唤醒等待的协程。
每个客户端连接到服务后,服务仍旧会启动两个协程
- recv协程负责接收客户端上行的报文,进行处理后将待发送的报文放入队列
- send协程负责消费队列的数据,它重复做以下逻辑
- 如果队列有数据则处理发送数据给客户端
- wait本连接对应的信号量,如果被唤醒则去共享内存中获取推送的消息放入队列中
此外这个版本还加入了一些基本的连接数监控,以及增加了连接建立时和连接断开时的处理阶段,来支持一些数据的初始化和清理工作。
解决的问题
- 解决了redis连接不够用的问题,单个worker承载3w个客户端连接时,对应的redis连接也只有一条
存在的问题
- 当大量设备处于同一组的时候,一个topic会触发大量的消息推送,cpu飙高,与推送信息相关的下游服务会有访问量的暴增,最终直接被冲垮重启。
- 接收协程处在wait阶段导致recv协程处理的数据发出去有延迟(最大为一个信号量wait的超时时间)
- wait信号量和post临界区资源时可能不匹配,也不能避免协程抢占临界区资源,精确同步难度大
第三版
第二版改完后,虽然有很多缺陷,但在线上跑了近两年的时间,这两年的时间里长连接数量从不到1w逐渐上涨到了接近100w,随着搭载了推送服务的sdk的设备越来越多,一些设备量大的分组一次消息发布需要推送几万个设备。这种不定期的瞬时大流量给我们推送后下游的服务带来了不小的麻烦。于是决定在推送服务内部加上流量控制,让推送的速率保持恒定。同时针对之前的一些问题,下决心再重构一下服务。
服务设计
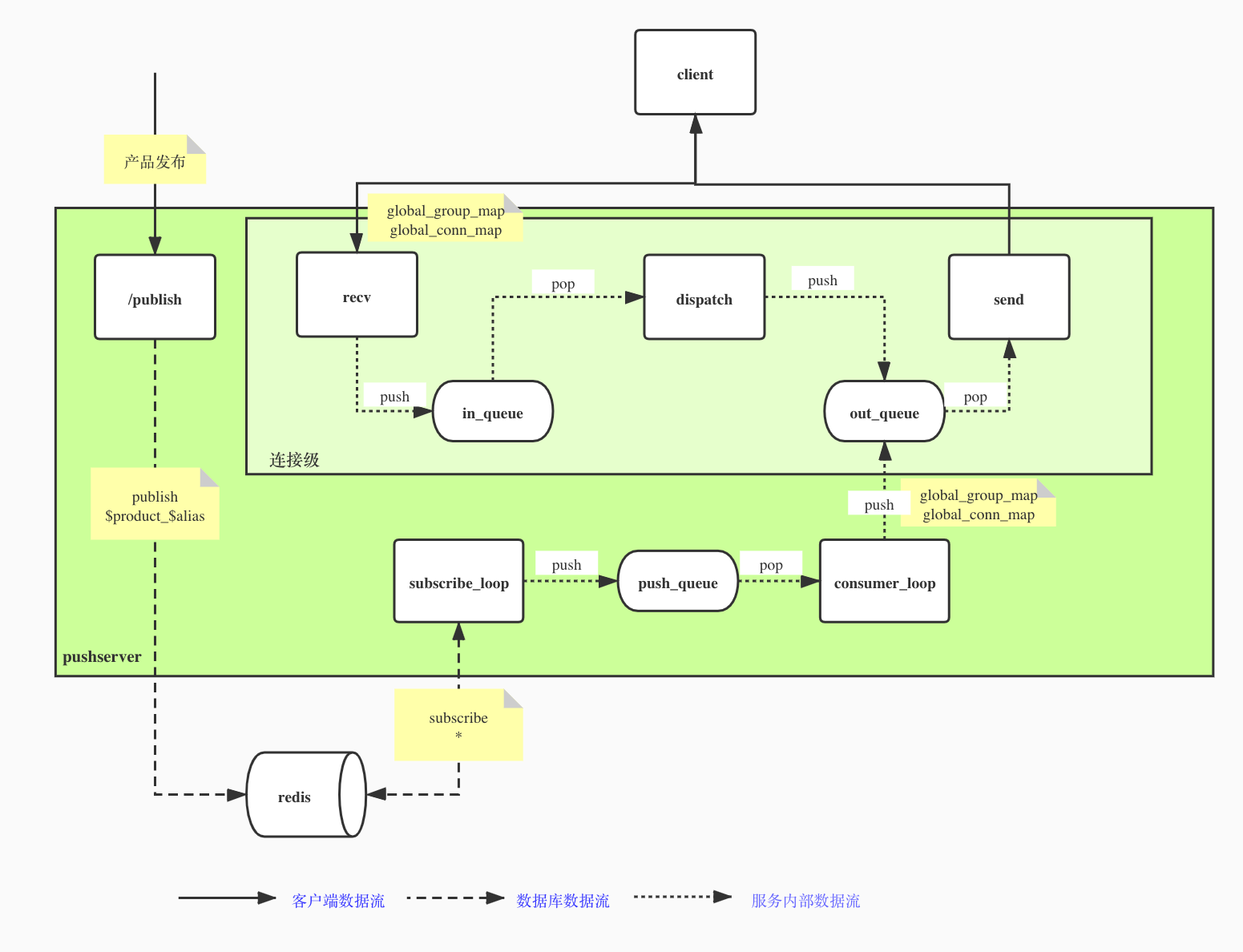
先来解决核心问题,为了维持恒定的推送速率,在服务里引入了一个消费推送信息的consumer协程,同时微调了一下subscribe协程的工作。
服务启动时分别创建一个全局的连接表(global_conn_map)和一个按(product_id+alias_key)维度划分的全局分组连接表(global_group_map)
subscribe协程仍然使用psubscribe订阅redis,拿到数据后这次不再post临界区资源了,而是将消息塞入push_queue队列,consumer协程负责消费这个队列,每次取出一条消息,然后根据消息从global_group_map获取待推送的设备连接列表,根据连接id,从global_conn_map拿到对应的发送队列,按照设置的速率向每个连接的里push消息。
这一版的实现里,我们新引入了一个dispatch协程,同时创建了两个队列来解耦接收和发送。客户端连接建立时,加入连接加入两个全局的表中(global_conn_map和global_group_map)
- recv协程,负责接收客户端的消息后放入in_queue
- send协程,负责从out_queue取出消息发送给客户端,由于没有其他逻辑,只要有数据要发送,send队列不会再阻塞了
- dispatch协程, 负责处理消息逻辑,从in_queue接收客户端消息,处理完后放入out_queue
同时把队列做了改造,封装了semaphore的api支持阻塞特性的 lua-resty-queue, 这样当从队列里pop不到数据时,可以一直阻塞直至超时。利用这个队列,可以把原先按组划分的信号量精细化到了每个连接上,这样可以更好的记录哪些推送成功了,哪些推送失败了,也保证了每个连接不会多抢占消费推送信息。
在解决了以上问题后,还做了一些其他功能的扩充:
- 集成prometheus client, 做了更完善的监控,包括错误码,推送成功/失败次数,连接持续时长等等
- 集成了etcd client, 支持动态的修改配置,特别是用于调整推送速率时不用再重启服务
- 加入了主动断开连接的功能,对于长时间无业务报文的连接,支持服务端主动断开
解决的问题
- 可以维持恒定的推送速率,降低推送消息后对其他服务产生的瞬间压力
存在的问题
- redis的pub/sub模式一旦客户端掉线就会丢失消息
- 待推送的队列保存在内存中,一旦重启消息就会丢失,由于业务上可以接受消息未及时送达,待连接重新建立上来时,会做一次重新推送的检查。
- 基于openresty的推送服务,即使连接数下降了,内存仍然维持在较高的水位,这个问题目前不是很好解决,由于nginx内存管理的限制,它更擅长的是处理http请求。
当前这版基本够用了,后续是否需要继续演进一切看业务需求。


