前一阵加了一个活跃连接数的监控,顺手发现了服务里一个协程泄露的坑,后面看了commit记录这个bug从这个项目开始就一直存在了。。。
0x0 背景
最近在ddsserver上加入了客户端活跃连接数的监控。这个服务是一个使用openresty开发的项目,连接数监控有现成的nginx c module,加入参数 –with-http_stub_status_module 重新编译openresty后在nginx.conf加入
stub_status on
在lua代码中直接可以访问这个内置变量 ngx.var.connections_active 来获取当前的连接数,将这个变量集成进prometheus监控里
monitor_logger:set("metric_connections", ngx.var.connections_active, {"active"})
在本地测试没有问题后就美滋滋地更新到线上了。
0x1现象
更新到线上后,在监控页面观察到发现这个服务的连接数量在持续上涨。
连接数持续上涨

从业务的其他监控上看,在凌晨时间段有明显的业务低峰期,但是这段时间内监控到的连接数却是没有明显减少
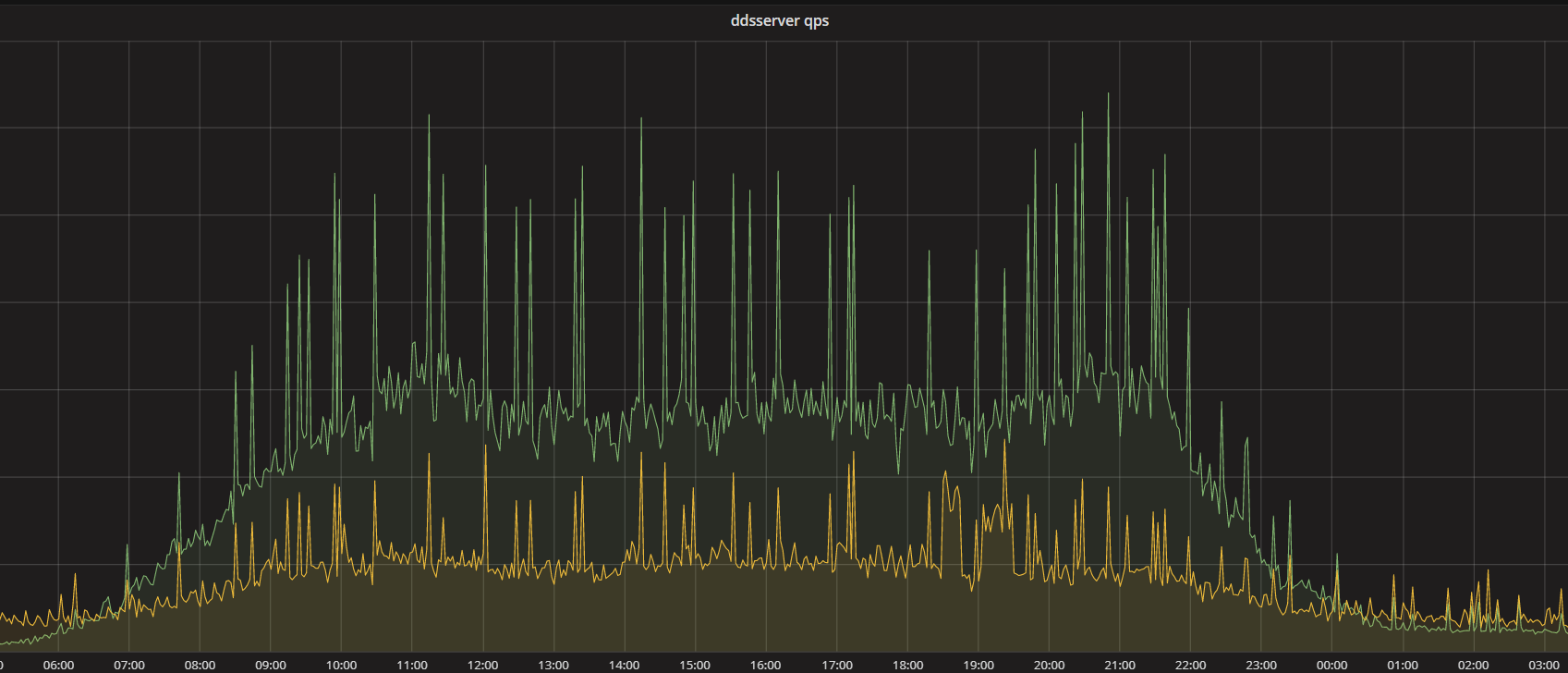
显然这两者的数据对不上,第一反应是监控的面板配置不对,反复确认后,监控接口获取数据确实是和grafana一致的。那么问题来了,难道是c模块统计有问题? 但是我们线上相同技术栈的另外一个websocket的推送服务,也是使用的这个模块来监控的,它统计到的websocket长连接数量是正确的(我们这边通过对比阿里云SLB连接数监控和服务监控的连接数做了比对是一致的)。
此时我登到了线上的机器看了一下服务实际的连接, 发现服务里有上百个CLOSE_WAIT的连接。
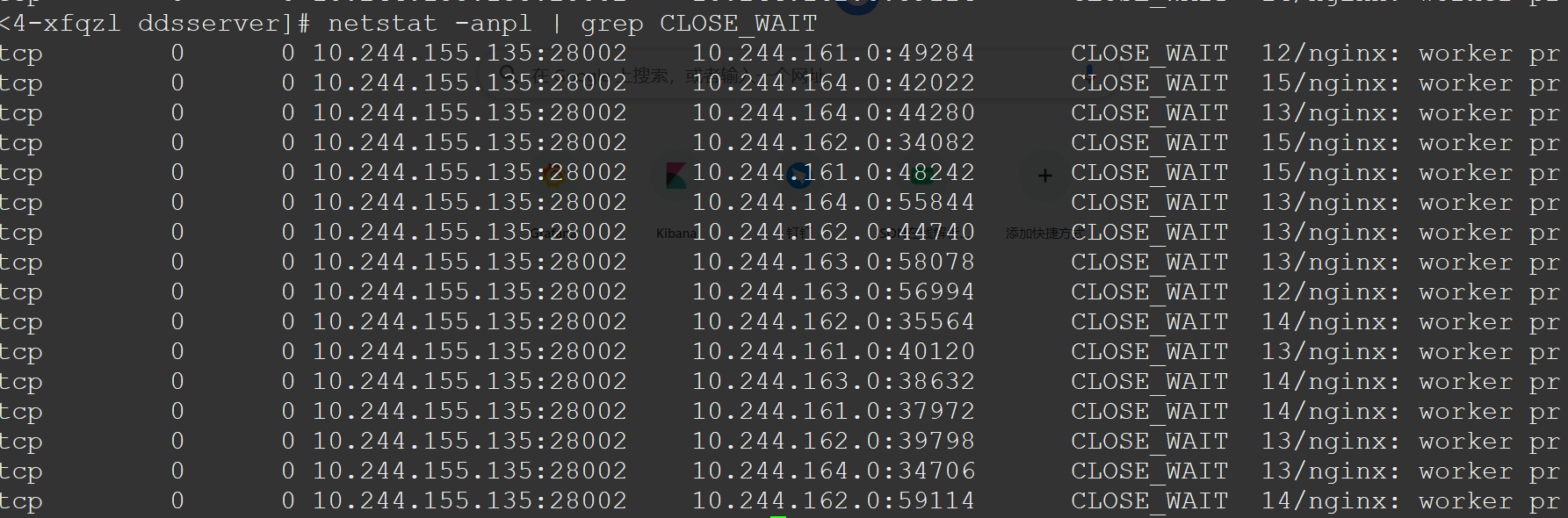
0x2 分析与复现
在TCP四次挥手的状态迁移图中,CLOSE_WAIT的状态通常是服务端收到了客户端的FIN, 但是服务端还未发送FIN给客户端,这个状态一般存在时间非常短。当服务中出现大量CLOSE_WAIT状态的连接时,通常说明服务端的代码有bug, tcp连接未能正确关闭。
我们在本地尝试了很多次请求也没有复现出来,因此推断是某些异常情况下才会导致连接未能正常关闭的。
后面又尝试了从netstat追踪到的CLOSE_WAIT连接的信息找对应的请求,但是由于线上都是容器化部署,又经过了一层代理,追踪到的tcp四元组和日志里打印的客户端外网的ip无法对应起来,于是我们在access阶段加入调试代码,把真实的连接的信息打印到日志里
if config.debug_close_wait then
ngx.log(ngx.INFO, "ip: ", ngx.var.realip_remote_addr, ", port: ", ngx.var.realip_remote_port)
end
这个调试日志上线后我们很快找出了这些CLOSE_WAIT状态的连接对应的请求,无一例外,这些异常的连接日志里,服务端都有一条相同的日志,内容如下,这条日志表明了服务端recv出错,客户端异常断开了连接
busserver recv frame error: failed to receive the first 2 bytes: client aborted
看到这个信息后我们在线下又模拟了这种情况,将音频发送到一半然后立刻端口连接,反复多次仍然没有成功复现。
再次查找日志发现有client abort 的请求也有正常关闭连接的,但是有一个很奇怪的现象产生CLOSE_WAIT的连接最后都是停在了一条相同的日志(具体日志就不贴了,涉及公司业务)。看上去processor节点发送给asr节点后卡死在这里了,再结合之前ddsserver上有内存泄露,大概率这里存在协程泄露。
这里先回过头来讲一讲服务使用的通信机制,服务使用了一条bus总线,所有节点间的通信都要通过bus, 比如processor要将音频请求发给asr节点,processor需要先将 数据写入bus的队列, 然后开始等待返回,busserver取出数据根据协议解析,将数据写入asr接收队列,asr节点处理完数据后再写回bus的队列,busserver再次取出数据并解析后将数据写入processor的接收队列,processor收到返回后继续处理。
这套通信框架充分使用了openresty的协程机制,如果没有非阻塞的调用,协程是不会让出cpu的,也就是说其他节点的协程是得不到调度的。
我们再次review代码,发现processor中会有非阻塞的网络io, 也就是在processor等待网络io的时候,其他协程也可以得执行,此时如果busserver出现异常退出后,processor节点等到io返回后继续执行,在发送完数据等待同步返回时就阻塞住了。
我们在processor中加入了模拟这种耗时的非阻塞操作,使用ngx.sleep(2)后再发送asr的text报文来放大影响,让其他节点有充分的时间先处理队列中的其他消息,果然在我们发送数据后立即断开连接,预期的CLOSE_WAIT出现了。
原因是processor在sleep结束后,将asr的text报文写入bus的队列后就开始等待busserver返回调用结果了,而在此期间sleep的时候,由于客户端断开连接,触发了busserver的异常处理,它在向每个节点发送完exit消息后就退出了,并没有等所有节点退出后再结束。而另一边processor还在阻塞在等待busserver返回调用结果,导致无法处理后面的消息,也就一直卡在这里,这也是之前导致内存泄露的元凶。
0x3 疑问
既然websocket连接上收到的了client abort的错误,我们的openresty服务也开启了lua_check_client_abort的检查,并且也注册了on_abort的回调函数。这个回调函数中,我们调用了ngx.thread.kill杀掉所有节点,并且释放连接,那为什么还有协程泄露呢?
我们在线下向回调函数中加入了调试日志,并模拟了出现CLOSE_WAIT的请求,奇怪的是确实没有任何日志打印出来,说明on_abort的回调并没有执行。
带着问题又去看了一遍官方文档对lua_check_client_abort的说明
According to the current implementation, however, if the client closes the connection before the Lua code finishes reading the request body data via ngx.req.socket, then ngx_lua will neither stop all the running “light threads” nor call the user callback (if ngx.on_abort has been called). Instead, the reading operation on ngx.req.socket will just return the error message “client aborted” as the second return value (the first return value is surely nil).
When TCP keepalive is disabled, it is relying on the client side to close the socket gracefully (by sending a FIN packet or something like that). For (soft) real-time web applications, it is highly recommended to configure the TCP keepalive support in your system’s TCP stack implementation in order to detect “half-open” TCP connections in time.
大致是说当前实现中,客户端关闭连接的时候,仍在使用了ngx.req.socket接收数据那么nginx既不会关闭当前这个请求的协程,也不会执行注册的on_abort回调函数,取而代之的是向ngx.req.socket返回一个"client aborted"的错误信息,因此我们注册的回调函数实际上并没有真正执行。
0x4 修复
分析完上面的结果,我们做了一版快速修复,就是在busserver异常退出的情况,直接用ngx.thread.kill杀掉所有节点,修复上线后从监控看连接数终于和业务QPS可以对上了,客户端和服务之间的CLOSE_WAIT连接也消失了。

当然更彻底的修复需要修改通信机制, 感觉有几种修复方式
- 在server退出时需要释放bus总线队列,这样可以使节点感知发送失败,从而可以做错误处理
- 节点与节点之间的通信加入超时机制,这是rpc调用里常见的方式,当然针对bus这套不是必需的,原因是它所有的处理都在一个nginx进程中
- busserver实现优雅退出,等待所有节点退出后才执行退出操作


